
DataStructure
DataStructure
Array vs Linked List
Array
最も基本的なデータ構造である配列(Array)は、論理的な格納順序と物理的な格納順序が一致しているため、インデックス(index)で該当する要素(element)にアクセスすることができます。つまり、検索したい要素のインデックス値が分かっている場合、Big-O(1)で該当する要素にアクセスできるという利点があります。つまり、ランダムアクセスが可能であるということです。
しかし、削除や挿入の過程では、該当する要素にアクセスして作業を完了した後(O(1))、追加の1つの作業をさらに行う必要があるため、より時間がかかります。例えば、配列の要素のうち1つを削除した場合、配列の連続的な特徴が壊れます。つまり、空きスペースが発生することになります。そのため、削除した要素よりも大きいインデックスを持つ要素をshiftしてあげるコストが発生し、この場合の時間の複雑さはO(n)になります。そのため、配列の削除機能に対するtime complexityの最悪の場合はO(n)になります。
挿入の場合も同様です。例えば、最初の場所に新しい要素を追加したい場合、すべての要素のインデックスを1つずつshiftしてあげる必要があるため、この場合もO(n)の時間が必要になります。
Linked List

この部分に対する問題点を解決するためのデータ構造が連結リストです。各要素は自分自身の次にどの要素があるかだけを覚えています。したがって、この部分だけを別の値に変えれば、削除と挿入をO(1)で解決することができます。
しかし、連結リストにも1つの問題があります。挿入したい場所に挿入する場合、論理的な保存順序と物理的な保存順序が一致しないため、最初の要素からすべてを確認する必要があります。これは、挿入してからソートするのと同じです。このプロセスにより、要素を削除または追加するために、その要素を見つけるためにO(n)の時間が追加で発生します。
結局のところ、連結リストデータ構造は、検索にもO(n)の時間計算量を持ち、挿入と削除にもO(n)の時間計算量を持ちます。それでも、完全に役に立たないデータ構造ではないため、私たちが学習するものです。この連結リストは、ツリー構造の基盤となるデータ構造であり、ツリーで使用するとその有用性が明らかになります。
Stack and Queue
Stack

スタック(Stack)は、後から入った要素が先に出てくる、または先に入った要素が後に出てくる、最後に入ったものが最初に出てくる(Last In First Out, LIFO / First In Last Out, FILO)という特徴を持つ、線形データ構造の一種です。スタックは、積み重ねる構造をしており、最初にスタックに入れた要素は一番下に積み上げられます。そのため、後から入った要素はその上に積み上げられ、呼び出す際には一番上にある要素が呼び出される構造です。
Queue

キュー(Queue)は、先に入った要素が先に出てくる(First In First Out, FIFO)という特徴を持つ、線形データ構造の一種です。スタック(Stack)とは対照的に、最初に入った要素が先頭で待ち、最初に処理される構造です。Java Collectionでは、Queueはインターフェースであり、Priority Queueなどの実装を使用することができます。
Tree
木構造(Tree)は、スタックやキューのような線形データ構造ではなく、非線形のデータ構造です。木構造は階層的な関係を表現するためのデータ構造です。この木構造というデータ構造は表現に重点を置いています。何かを保存して取り出すことに固執するのではなく、木構造というデータ構造を考えてみましょう。
木構造を構成する要素(用語)
- Node (ノード) : 木構造を構成する各要素を指します。
- Edge (枝) : 木構造を構成するために、ノードとノードを結ぶ線を指します。
- Root Node (ルートノード) : 木構造で最上位にあるノードを指します。
- Terminal Node ( = leaf Node, 葉ノード) : 下位に他のノードが接続されていないノードを指します。
- Internal Node (内部ノード, 葉以外のノード) : 葉ノードを除くすべてのノードで、ルートノードも含まれます。
Binary Tree (二分木)
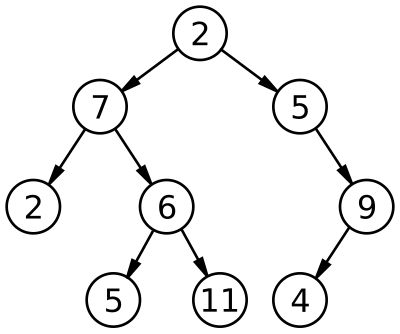
二分木(Binary Tree)は、ルートノードを中心に2つのサブツリー(大きなツリーに属する小さなツリー)に分かれます。また、分かれた2つのサブツリーもまた二分木でなければなりません。再帰的な定義であるため、理解するのは簡単ではありませんが、ルートノードから分かれた2つのサブツリーは、それぞれ別の二分木となります。また、空の集合も二分木に含める必要があります。これは、再帰的に条件を確認していく過程で、葉ノードに到達した際に、定義が満たされるためです。自然に、ノードが1つだけの場合でも二分木の定義に満たすことになります。
ツリーでは、各レベルに番号を付けて、それをツリーのLevel(レベル)と呼びます。レベルの値は0から始まり、したがってルートノードのレベルは0になります。そして、ツリーの最大のレベルを指して、そのツリーのheight(高さ)と呼びます。
完全二分木、ポーフル二分木、完全二分木 すべてのレベルがいっぱいの二分木を完全二分木といいます。上から下まで、左から右まで順番に詰められた二分木を完全二分木といいます。すべてのノードが0個または2個の子ノードだけを持つ二分木を完全二分木といいます。配列で構成された二分木では、ノードの数がn個であり、rootが0ではなく1から始まる場合、i番目のノードに対してparent(i) = i/2、left_child(i) = 2i、right_child(i) = 2i + 1のインデックス値を持ちます。
BST (Binary Search Tree)
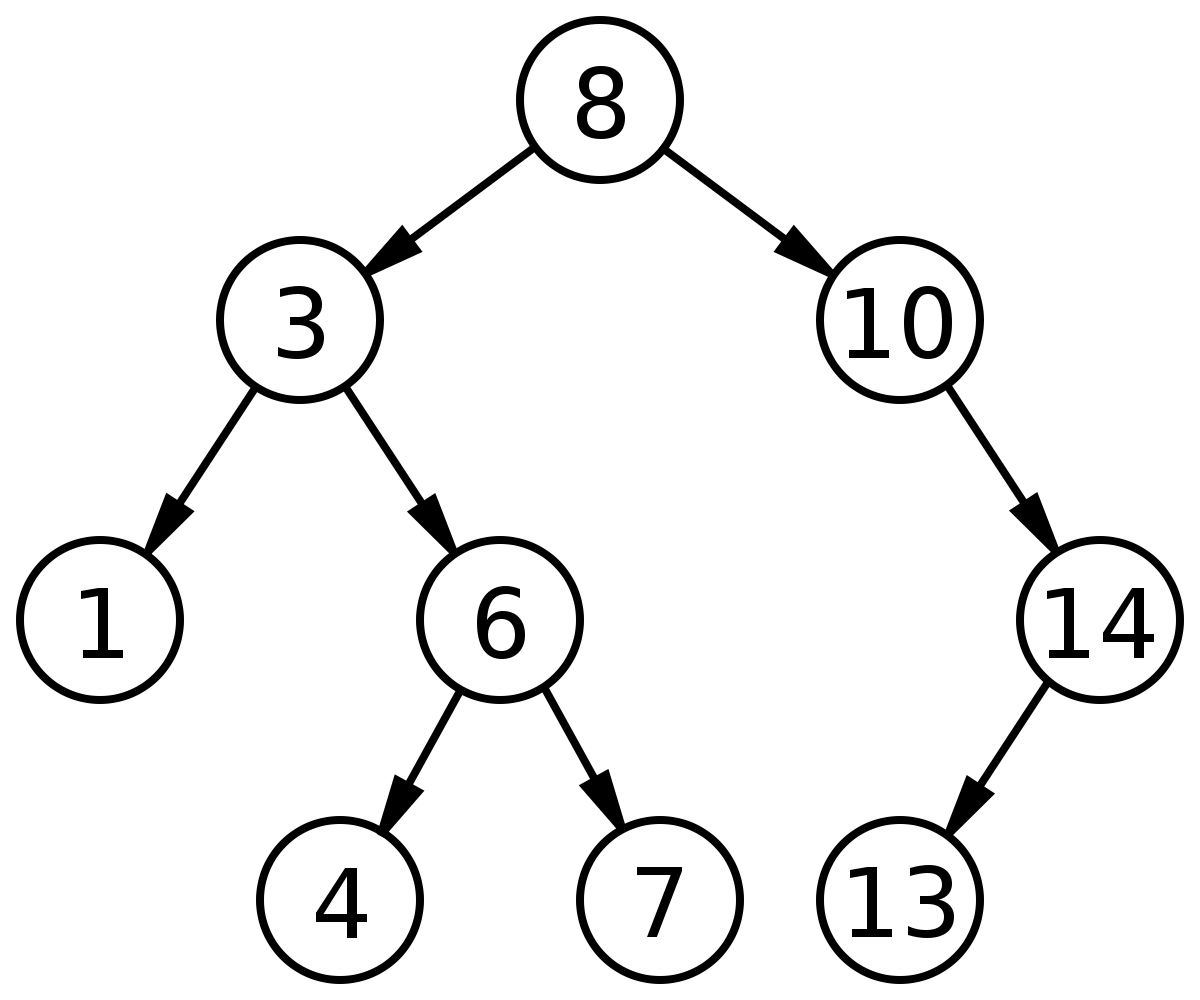
効率的な検索を行うためには、単にどう探すかを考えるだけではなく、効率的な検索を行うためのデータ構造を考えることが重要です。バイナリサーチツリーはバイナリツリーの一種であり、データを保存するためのルールがあります。そして、そのルールは特定のデータの位置を見つけるために使用することができます。
- ルール二分探索木のノードに保存されたキーは、ユニークでなければなりません。
- ルール 2. 親のキーは左の子ノードのキーよりも大きいです。
- ルール 3. 親のキーは右の子ノードのキーよりも小さいです。
- ルール 4. 左右のサブツリーも二分探索木である必要があります。
二分探索木の検索操作は、O(log n)の時間複雑度を持ちます。実際には、正確にはO(h)と表現する方が正確です。木の高さが1つずつ増えるたびに、追加できるノードの数が2倍に増えるためです。ただし、このような二分探索木は、Skewed Tree(歪んだ木)になる可能性があります。保存順序によって、ノードが常に1方向にしか追加されない場合があり、性能に影響を与え、最悪の場合の検索時間複雑度がO(n)になります。
配列よりも多くのメモリを使用してデータを保存しましたが、同じ検索に必要な時間複雑度になる非効率な状況が発生します。これを解決するために、再平衡化技術が登場しました。バランスを取るための木構造の再調整を再平衡化と呼びます。この技術を実装したツリーには、多数の種類があり、その中でRed-Black Treeなどがあります。
Binary Heap
ヒープ(Heap)は、Treeの形式を持つデータ構造で、Treeの中でも配列に基づいた完全二分木である。配列にTreeの値を入れる場合、0番目を飛ばして1番目からルートノードが始まる。これはノードの固有番号の値と配列のindexを一致させるためである。ヒープには最大ヒープ(max heap)と最小ヒープ(min heap)の2種類がある。
Max Heapとは、各ノードの値が該当するchildrenの値以上であるcomplete binary treeを指す。(Min Heapはその逆である。)
Max HeapではRoot nodeにある値が最大値であるため、最大値を探すのにかかる操作のtime complexityはO(1)になります。また、complete binary treeであるため、配列を使用して効率的に管理できます。(つまり、random accessが可能です。Min heapでは最小値を探すのにかかる操作のtime complexityがO(1)です。)しかし、heapの構造を維持するためには、削除されたルートノードを置き換える別のノードが必要になります。ここでheapは、最後のノードをルートノードに置き換えて、再びheapifyプロセスを通じてheap構造を維持します。この場合、最大値または最小値にアクセスするためにO(log n)の時間複雑度がかかるようになります。
Red Black Tree
RBT(Red-Black Tree)は、BST(Binary Search Tree)を基礎とする木構造のデータ構造です。データをRBTに保存すると、Search、Insert、DeleteにはO(log n)の時間複雑度が必要です。同じ数のノードがある場合、深さを最小限に抑えて時間複雑度を減らすことが重要なアイデアです。同じ数のノードがある場合、深さが最小になるのは、treeがcomplete binary treeの場合です。
Red-Black Treeの定義
Red-Black Tree は、以下の性質を満たす BST です。
- 各ノードは赤または黒である。
- ルートノードは黒である。
- 各葉ノード(NILノード)は黒である。
- 赤いノードの2つの子ノードは両方とも黒である。(すなわち、赤いノードは連続して現れることはない)
- あるノードから始まり、そのノードの子ノードたちを葉ノード(NILノード)までたどるそのすべての経路には、同じ数のBlackノードが含まれる。この数をそのノードの「Black-Height」と呼びます。cf) Black-Height: ノードxから、ノードxを含まない葉ノードまでの単純なパス上にある黒いノードの数
Red-Black Treeの特徴
- Red-Black Treeは、Binary Search Treeであり、BSTの特徴をすべて備えています。
- Root ノードから leaf ノードまでの全てのパスのうち、最小パスと最大パスの長さ比率が 2 以上にならない状態を「バランスが取れている (balanced)」と言います。
- ノードの子が存在しない場合、子を指すポインターにはNIL値が格納されます。このようなNILを葉ノードと見なします。
RBTは、BSTの挿入、削除操作過程で発生する問題を解決するために作られたデータ構造です。具体的には、以下のような手順を踏んでいます。
挿入操作: まず、BSTの特性を維持しながらノードを挿入します。そして、挿入されたノードの色を赤にします。赤にする理由は、Black-Heightの変更を最小限に抑えるためです。挿入後、RBTの特性が違反している場合は、ノードの色を調整し、Black-Heightが違反している場合は回転を行って高さを調整します。これにより、同じ高さにあるinternal nodeのBlack-Heightが同じになり、最小経路と最大経路のサイズ比が2未満になります。
削除操作: 削除も挿入と同様に、BSTの特性を維持しながらノードを削除します。削除されるノードの子の数に応じて、回転方法が異なります。そして、削除されるノードの色がBlackであれば、Black-Heightが1減少した経路にblack nodeが1個追加されるように回転し、ノードの色を調整します。削除されたノードの色がredであれば、Violationが発生しないため、RBTはそのまま維持されます。
Java CollectionのTreeMapも内部的にはRBTで構成されており、HashMapのSeparate Chainingでも使用されています。そのため、効率が良く、重要なデータ構造と言えます。
※参考リンク
・https://en.wikipedia.org/wiki/Red%E2%80%93black_tree#Insertion
Hash Table
ハッシュは、内部的に配列を使用してデータを保存するため、高速な検索速度を持っています。データ固有のインデックスによってアクセスするため、特定の値を検索する場合の平均時間計算量がO(1)になります。(常にO(1)ではなく、衝突によって平均時間計算量がO(1)になることがあるためです。)しかし、問題はこのインデックスで保存されるキー値が不規則であるということです。
そのため、特別なアルゴリズムを使用して保存するデータと関連する固有の数値を生成し、それをインデックスとして使用します。特定のデータが保存されるインデックスは、そのデータだけの固有の位置であるため、挿入操作時に他のデータの間に挟み込まれたり、削除時に他のデータで埋める必要がないため、追加のコストがないように操作が設計された構造です。
Hash Function

ハッシュは内部的に配列を使用してデータを保存するため、高速な検索速度を持っています。特定の値を検索するには、データ固有のインデックスにアクセスするため、平均ケースの時間複雑度はO(1)になります。(常にO(1)ではなく、平均ケースに対してO(1)であるのは、衝突のためです。)しかし、問題はこのインデックスに保存されるキー値が不規則であるということです。
そのため、特別なアルゴリズムを使用して保存するデータに関連する一意の数字を生成し、それをインデックスとして使用します。特定のデータが保存されるインデックスは、そのデータ固有の一意の位置であるため、挿入操作時に他のデータの間に挟まる必要がなく、削除時に他のデータで置き換える必要がないため、追加のコストがないように作られた構造です。
しかし、不十分なハッシュ関数を使用してキー値を決定すると、同じ値が導き出される可能性があります。これにより、同じキー値に複数のデータが1つのテーブルに存在することができるようになりますが、これをCollisionと呼びます。Collision:異なる2つのキーが同じインデックスにハッシング(ハッシュ関数を使用して計算されることを意味する)されると、同じ場所に保存できなくなります。
では、良いハッシュ関数にはどのような条件が必要でしょうか?一般的に、良いハッシュ関数は、キーの一部分を参照してハッシュ値を作成せず、キー全体を参照してハッシュ値を生成します。ただし、良いハッシュ関数は、キーがどのような特性を持っているかに応じて異なる場合があります。
ハッシュ関数を必ず1:1にすることよりも、衝突を最小限に抑える方向性で設計し、発生する衝突に対処することがより重要です。1:1の対応がほとんど不可能であり、そのようなハッシュ関数を作成しても、それは単なる配列と同じになり、メモリを余計に使用してしまいます。
衝突が増えるほど、検索に必要な時間複雑度がO(1)からO(n)に近づいてしまいます。不十分なハッシュ関数は、ハッシュを適切に使用できなくなるため、選択するハッシュ関数はハッシュテーブルの性能向上に不可欠です。
したがって、既にハッシュ化されたインデックスに他の値が入っている場合、新しいデータを保存する別の場所を探してから保存する必要があります。したがって、衝突の解決は必須であり、その解決方法について理解することが重要です。
Resolve Conflict
基本的な2つの方法を見てみましょう。ハッシュの衝突を解決するためのさまざまな方法がありますが、次の2つの方法を応用したものであるためです。
1. オープンアドレス方式

ハッシュの衝突が発生した場合(つまり、挿入しようとするハッシュバケットが既に使用中の場合)、別のハッシュバケットにそのデータを挿入する方法です。バケットとは、データを保存するためのスペースで、バスケットのような概念です。別のハッシュバケットとは、どのようなハッシュバケットを指すのでしょうか?
オープンアドレス法とも呼ばれるこのアルゴリズムは、衝突が発生した場合、データを保存する場所を探して彷徨う方法です。最悪の場合、空いているバケットを見つけることができず、検索を開始した位置まで戻ることができます。このプロセスでも、いくつかの方法がありますが、以下の3つについて見てみましょう。
- 線形プロービング:空のバケットを見つけるまで順次検索が続けられます。
- 二次探査法:2次関数を使用して、探索する位置を見つけます。
- ダブルハッシング:1つのハッシュ関数で衝突が発生した場合、2次ハッシュ関数を使用して新しいアドレスを割り当てます。上記2つの方法と比較して、多くの演算量を要求します。
2. eparate Chaining 方式 (分離連結法)

一般的に、Open AddressingはSeparate Chainingよりも遅くなる傾向があります。Open Addressingの場合、ハッシュバケットの密度が高くなるほど、Worst Case発生頻度が高くなるためです。一方、Separate Chainingの場合、補助ハッシュ関数を使用してハッシュ衝突を防ぐことができれば、Worst Caseに近づく頻度を減らすことができます。Java 7ではSeparate Chaining方式を使用してHashMapを実装しています。Separate Chaining方式には2つの実装方法があります。
-
リンクリストを使用する方法
それぞれのバケット(bucket)をリンクリスト(Linked List)にして、Collisionが発生した場合には対応するbucketのlistに追加する方法です。リンクリストの特徴をそのまま受け継いでいるため、削除または挿入が簡単です。ただし、欠点もそのまま受け継いでおり、小さなデータを保存する場合にはリンクリスト自体のオーバーヘッドが負担になることがあります。もう一つの特徴として、Open Addressing方式で継続的にバケットを使用する場合に比べて、テーブルの拡張を遅らせることができます。
-
ツリーを使用する方法(Red-Black Tree)
基本的なアルゴリズムはSeparate Chaining方式と同じですが、リンクリストの代わりにツリーを使用する方法です。データ数が少ない場合はリンクリストを使用するべきであり、ツリーはメモリ使用量が多いためです。データ数が少ない場合のWorst Caseを見ると、ツリーとリンクリストのパフォーマンス差はほぼありません。したがって、データ数が少ない場合はメモリ面から見てリンクリストを使用することが望ましいです。
データが少ないとは、どの程度少ないことを意味するのでしょうか?先に述べたように、基準は1つのハッシュバケットに割り当てられたキーと値のペアの数によって決まります。このキー-値ペアの数が6個、8個を基準に決定します。基準が2つあることが奇妙に感じるかもしれません。7はどこに行ったのでしょうか?リンクドリストの基準とツリーの基準を6と8に設定したのは、変更にかかるコストを減らすためです。
ある状況を仮定してみましょう。ハッシュバケットには6つのキー-値ペアが含まれていました。そして、1つの値が追加されました。基準が6と7であれば、データ構造をリンクドリストからツリーに変更する必要があります。そして、すぐに1つの値が削除された場合、再びデータ構造をツリーからリンクドリストに変更する必要があります。各データ構造に移行する基準が1であれば、切り替えのコストがあまりにも多く必要になることになります。そこで、余裕を持たせて基準を設定したのです。したがって、データの数が6個から7個に増えた場合、リンクドリストのデータ構造を採用しているはずであり、8個から7個に減少した場合はツリーのデータ構造を採用しているはずです。
Open Address vs Separate Chaining
両方の方式はWorst CaseでO(M)であるが、Open Address方式は連続した領域にデータを格納するため、Separate Chainingに比べてキャッシュ効率が高くなります。したがって、データの数が十分に少ない場合、Open Address方式の方がSeparate Chainingよりも性能が良い場合があります。もう1つの違いが存在します。Separate Chaining方式に比べ、Open Address方式はバケツを継続的に使用します。したがって、Separate Chaining方式はテーブルの拡張をより遅らせることができます。
補助ハッシュ関数
補助ハッシュ関数 補助ハッシュ関数(supplement hash function)の目的は、keyのハッシュ値を変形させて、ハッシュ衝突の可能性を減らすことです。Separate Chaining方式を使用する場合に併用され、補助ハッシュ関数によってWorst Caseに近づく場合を減らすことができます。
ハッシュバケットの動的拡張(Resize)
ハッシュバケットの数が少ない場合はメモリ使用を節約できますが、ハッシュ衝突によるパフォーマンスの低下が発生します。そのため、HashMapはkey-valueペアデータ数が一定数を超えると、ハッシュバケットの数を2倍に増やします。このように拡大することで、ハッシュ衝突によるパフォーマンスの低下問題をある程度解決できます。また、曖昧な ‘一定数を超える’という表現が登場しました。ハッシュバケットサイズを2倍に拡張する閾値は、現在のデータ数がハッシュバケット数の75%になるときです。0.75という数字はロードファクタと呼ばれています。
Graph
頂点と辺の集合、グラフ
cf) 木もグラフであり、その中でもサイクルを許容しないグラフを指す。
グラフに関する用語集
無向グラフと有向グラフ(有向グラフ)
頂点と辺の関係において、方向性がないグラフを無向グラフといい、辺に方向性が含まれているグラフを有向グラフと呼ぶ。
- Directed Graph (Digraph)
V = {1, 2, 3, 4, 5, 6}
E = {(1, 4), (2,1), (3, 4), (3, 4), (5, 6)}
(u, v) = vertex u에서 vertex v로 가는 edge
- Undirected Graph
V = {1, 2, 3, 4, 5, 6}
E = {(1, 4), (2,1), (3, 4), (3, 4), (5, 6)}
(u, v) = vertex u와 vertex v를 연결하는 edge
次数(Degree)
無向グラフで、各頂点(Vertex)に接続された Edge の数を次数という。有向グラフでは、辺に方向性が存在するため、次数は2つに分かれる。各頂点から出る辺の数を出次数(Outdegree)、入る辺の数を入次数(Indegree)と呼ぶ。
重みグラフ(Weight Graph)と部分グラフ(Sub Graph)
重みグラフとは、辺に重み情報を置いて構成したグラフを指す。反対に、すべての辺の重みが同じグラフを非重みグラフという。部分集合に似た概念として、部分グラフというものがある。部分グラフとは、元のグラフの一部の頂点と辺からなるグラフを指す。
グラフを実装する2つの方法
隣接行列 (adjacent matrix) : 正方行列を使用する方法
対応する位置のvalue値を通じて、vertex間の接続関係をO(1)で確認することができる。Edgeの数に関係なく、V^2のSpace Complexityを持つ。Dense graphを表現する場合に適した方法である。
隣接リスト (adjacent list) : 関連リストを使用する方法
vertexの隣接リストを確認する必要があるため、vertex間が接続されているかを確認するのに時間がかかる。Space ComplexityはO(E+V)である。Sparse graphを表現するのに適した方法である。
グラフの探索
グラフは頂点の構成だけでなく、エッジの連結にも規則性が存在しないため、探索が複雑である。したがって、グラフのすべての頂点を探索するための方法には、以下の二つのアルゴリズムを基礎としている。
深さ優先探索 (Depth First Search: DFS)
グラフ上である任意の1つの頂点から接続されている1つの頂点だけに向かって探索する方法を優先して探索する方法です。 接続できる頂点がある限り、接続された頂点に向かって進み続け、もはや接続できる頂点がない場合は、戻って接続できる頂点があるかどうか確認する必要があります。迷路検索のように、行き来する場合があります。 どのデータ構造を使用する必要がありますか?スタックです。 時間計算量:O(V + E)…頂点数+辺数
幅優先探索 (Breadth First Search: BFS)
グラフ上である任意の1つの頂点から接続されているすべての頂点に向かって進む方法です。 Tree でのLevel Order Traversal形式で進行されることになります。BFS では、Queue を使用して頂点の連絡の順序を記録します。最初に、検索を開始する頂点をQueueに入れます(enqueue)。そして、dequeueをしながら、dequeueする頂点とエッジで接続された頂点をenqueueします。つまり、頂点を訪問した順序でqueueに保存する方法を使用します。
時間計算量:O(V + E)…頂点数+辺数
!すべてのエッジに重みが存在しないか、すべてのエッジの重みが同じ場合、BFSで求めた経路は最短経路です。
Minimum Spanning Tree
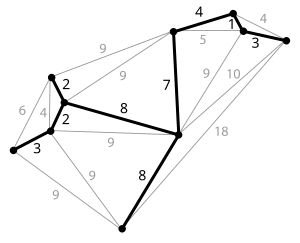
グラフGのspanning treeの中で、edge weightの合計が最小のものを指します。ここで言うspanning treeは、グラフGの全ての頂点がcycleなしで接続された形を指します。
Kruskal Algorithm
初期化作業として、edgeがない状態でvertexだけでグラフを構成します。そして、最小の重みを持つedgeから調べます。そのために、Edge Setをnon-decreasingにsortingする必要があります。そして、最小のweightに対応するedgeを追加しますが、グラフにcycleが生じない場合にのみ追加します。spanning treeが完成すると、すべての頂点が接続された状態で終了し、完成しないグラフについてはすべてのedgeについて判断が行われると終了します。
どのようにcycle生成の有無を判断するのか?
グラフの各頂点にset-idというものを追加します。そして、初期化の過程で、1からnまでの値で各頂点を初期化します。ここで、0はどのedgeとも接続されていないことを意味します。そして、接続するたびにset-idを一つに統一し、値が同じset-idの個数が多いset-id値に統一します。
Time Complexity
- エッジの重みを基準にsorting - O(E log E)
- サイクル生成の判断と
set-idを統一 - O(E + V log V) => 全体の時間計算量 : O(E log E)
プリム法
初期化過程で、1つの頂点から構成される初期グラフAを構成する。そして、グラフA内にある頂点から外部の頂点間のエッジを接続するが、その中でも最小の重みを持つエッジを通じて接続される頂点を追加する。どの頂点であっても、エッジの重みを基準に接続する。このように接続された頂点は、グラフAに含まれる。このプロセスを繰り返し、全ての頂点が接続された時点で終了する。
Time Complexity
=> 全体の時間計算量 : O(E log V)
※ 参考資料
・wikipedia
Comments